

모각코 다섯 번째 회의 때는 각자 공부한 내용에 대해 소개하는 시간을 가졌습니다!
저는 분산 시스템에서의 성능 개선 알고리즘을 찾아가면서 공부해봤습니다. 많은 방법이 있지만, 그 중에서 RAFT 알고리즘에 대해 간단하게 살펴봤는데요, 한 번 시작해볼까요~?
✏️ PART5. 분산 시스템에서의 성능 개선 알고리즘
1. 분산 시스템 성능 개선 관련 공부의 목적
분산 시스템 환경에서 여러 작업을 실행하는 과정에서 packet 손실이나, 중복 전송 혹은 delay 등의 문제가 발생합니다. 성능저하를 야기하는 여러 요인 가운데 노드와 네트워크 관점에서 문제를 해결하는 알고리즘을 소개하기 위해 공부를 진행해봤습니다.
2. 분산 시스템 성능 개선과 관련한 알고리즘
2-1. Raft 알고리즘의 배경
- 모든 노드가 동일한 상태를 유지하도록 하고, 일부 노드에 결함이 생기더라도 전체 시스템이 문제 없이 동작하도록 만들기 위해 고안된 “합의 알고리즘”의 일종입니다.
Raft의 등장 이전에는 분산 시스템의 거장 Lesile Lamport에 의해 만들어진 Paxos가 대세를 이루었습니다. 하지만, 스탠포드 대학의 학생인 본인들이 Paxos 알고리즘을 이해하는데 거의 1년 가까이 걸릴 정도로 어려워서 새로운 합의 알고리즘을 만들려고 했다고 합니다.
아래 그림은 2014년에 발표된 [In Search of an Understandable Consensus Algorithm] 논문에 실린 Raft 알고리즘과 Paxos 알고리즘에 대한 학생들의 생각에 대한 설문조사 지표입니다.

학생들은 Paxos는 구현도 어렵고 이해하기도 어렵다고 생각하는 반면, Raft알고리즘은 보다 이해하고 받아들이기 쉽다고 한 것을 알 수 있습니다.
2-2. Raft 알고리즘의 설명
* 기존 기법(단순한 Client - Server model) 설명

클라이언트가 서버로 요청을 보내고 서버가 요청에 따라 적절한 응답을 전달

노드,즉 Client 가 늘어날 경우 서버 과부하 등의 가용성 문제가 발생할 가능성 존재
이런 문제를 해결하기 위해 Raft 알고리즘을 씁니다!
Raft 알고리즘과 같은 분산 합의 알고리즘은 다음 세가지 속성합의를 가져야 합니다.
= Agreement + Validity + Termination
즉, 모든 올바른 프로세스는 동일한 값 유효성에 동의해야 하고 결국 값은 모든 올바른 프로세스에 의해 결정된다는 것이죠.
또한 분산 시스템에서 네트워크 분할이 있는 경우 일관성 또는 가용성 중에서 선택해야 합니다.
여기서 “가용성”이란 “다수의 서버가 동작할 수 있고 서로 통신이 가능한 상황이라면, 모든 기능은 동작해야한다”는 것을 뜻합니다.
예를 들어, 5개의 클러스터로 구성되어 있으면 최대 2개의 장애 허용성을 가지고 각 서버는 일시중단으로 여겨지며 나중에 복구된다는 것이죠.
“일관성”은 “시스템 타이밍에 의존하지 말아야 한다”는 뜻이다. (고장난 timer와 급격한 메시지 지연은 가용성 문제를 일으킬 수 있습니다 )
Paxos,Chandra-Toueg,Raft 와 같이 다양한 합의 알고리즘 중에서도
Raft는 = Replicated and Fault Tolerant의 약자로, 복제를 의미하며 내결함성을 동시에 구현할 수 있습니다.
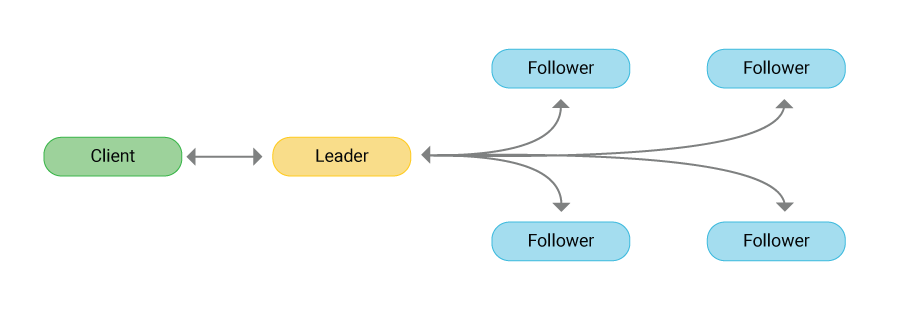
분산 시스템에서 모든 노드는 아래의 세 가지 중 하나의 상태를 가집니다.
일반적으로 하나의 리더와 나머지 팔로워들로 구성되며, 후보자는 오직 리더가 없거나 무응답 상태일 경우에만 일시적으로 존재합니다.
리더(Leader)
- 클러스터를 대표하는 하나의 노드, 리더는 클라이언트가 클러스터로 보낸 모든 명령의 수신 및 전파, 응답을 전담
- 리더는 자신의 상태 메시지(heartbeat)를 주기적으로 모든 팔로워에게 전파
팔로워(Follower)
- 리더가 존재하는 한 나머지 노드는 이 상태를 유지
- 리더로부터 전파된 명령을 처리하는 역할만 담당
후보자(Candidate)
- 리더가 없는 상황에서 새 리더를 정하기 위해 전환된 팔로워의 상태를 의미
- 리더로부터 일정 시간 이상 상태 메시지(heartbeat)를 받지 못한 팔로워는 후보자로 전환
2-3. Raft 알고리즘의 동작원리
리더는 수신된 명령에 대한 로그를 생성해 로컬에 저장한 뒤 모든 팔로워에게 복제하여 전달
🔽
각 팔로워는 전달받은 로그에 대한 응답을 다시 리더에게 보냄
🔽
리더가 수신한 정상 응답 수가 클러스터 전체 노드의 과반수이면, 리더는 로그를 통해 전파된 명령을 클러스터의 모든 노드가 동일하게 수행하도록 한 뒤 클라이언트에게 수행 결과 리턴
🔽
명령 처리를 제때 처리하지 못한 팔로워가 있더라도, 그 팔로워는 정상 상태로 복구된 뒤 클러스터와 연결이 재개되면 리더로부터 명령 처리 기록이 포함된 로그들을 다시 전달받아 순차적으로 수행 (클러스터 전체의 최신화 및 동기화)
▶ 리더 선출 (Leader Election) 방법
임기 (Term): 이 값은 새로운 선거가 시작된 시점부터 그 선거로 선출된 리더가 리더로서 기능하는 동안까지의 시간을 대표
선거 타임아웃 (Election Timeout): 팔로워 상태의 노드가 후보자로 변환되기까지 대기하는 시간
하트비트 (Heartbeat): 리더가 다른 모든 팔로워에게 일정 시간 간격으로 반복 전달하는 메시지, 이 메시지에는 클라이언트의 명령 전파를 위한 로그가 포함되지 않고, 리더가 자신의 상태를 유지하는 수단으로만 기능
▶ 리더 노드에 문제가 생겼을 경우
- 자신에게 주어진 선거타임아웃 이내 리더로부터 어떠한 메시지도 받지 못한 팔로워 노드는 즉시 후보자로 전환
- 클러스터의 임기 1 증가 후 새로운 리더 선출 시작
▶ 과반을 얻지 못했을 경우
- 그대로 해당 임기를 종료하고 새 임기와 함께 재선거를 시작
- 리더가 없을 경우 클러스터 관리 기능 전체를 멈추게 만듦
▶내결함성을 위한 최적의 노드 수
- 합의 알고리즘을 채택한 분산 시스템에서는 전체 노드 수를 가급적 3개 이상의 홀수로 유지하는 것이 권장
우리는 이런 Raft 알고리즘을 통해 Fail-stop(실패 중지), Network partition(네트워크 분할), Fail-recover(실패 복구), Byzantine failure(비잔틴 장애) 등을 처리할 수 있습니다!
※ 비잔틴 장애
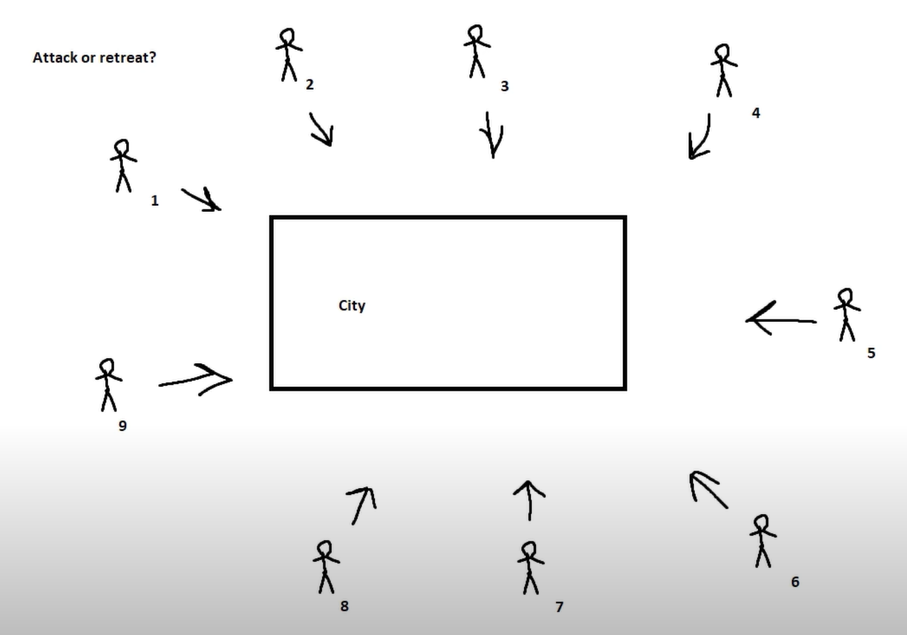
지리적으로 떨어져 있는 서로 다른 장군들이 하나의 성을 함락시키기 위해 공격 방법을 합의하는 것에 대한 문제입니다.
장군들이 공격하거나 후퇴하기 위해서는 동의를 얻어야 하고 모든 장군이 합의에 도달하는 한, 즉, 공격을 하든 후퇴를 하든, 협력적으로 결정에 동의한다면 아무런 문제가 없습니다.
가정된 상황은
- 각 장군들이 합동하여 과반수 이상이 출병해야만 적에게 승리할 수 있음.
- 각 장군들은 전령(messenger)를 통해서 연락을 주고 받음.
- 각 장군들은 근처의 장군에게 연락함.
장군들 중 배신자가 존재할 수도 있고, 배신자는 실제 전파받은 공격계획과 다른 내용을 전파할 수 있다. 따라서, 메시지가 중간에 훼손될 수 있다.
여기서 메시지가 늦게 전달되거나, 훼손될 수 있거나, 없어질 수 있다는 사실이 관건이다.
이런 비잔틴 장애 허용을 만드는 알고리즘은 중 하나가 Raft 알고리즘인 셈이다.
3. 결론
- Raft 논문에서는 성능 항목은 간략하게 나타나 있습니다. 우선, 성능과 관련된 항목은 새로운 리더가 선출되기 까지 리더가 없이 대기하는 시간이 얼마나 짧은지를 선거 타임 아웃 시간 파라미터마다 보여줍니다.
- 저자들은 선거 상황 자체를 가혹하게 만들기 위해 일부러 로그를 다르게 저장해서 일부 노드는 선거에서 의도적으로 패배할 수 밖에 없게 설정해 두었습니다.
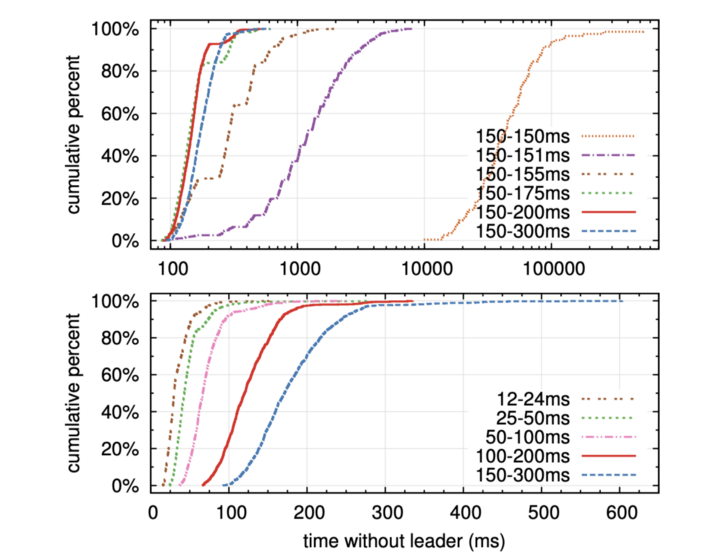
- 위 그래프는 랜덤으로 설정되는 타임아웃 시간 범위가 짧은 경우입니다.
- 예를 들어, 고정된 타임아웃 시간을 가진 150–150ms의 경우 투표가 결렬되는 경우가 많아 10초(10000ms) 이상까지 리더가 존재하지 않는 상황이 나타납니다.
- 아래 그래프는 각 논문의 저자들이 주장하고 싶었던 근거가 될 것 같은데 랜덤 타임아웃의 범위가 클 수록 투표가 분할되지 않고 안정적으로 리더를 빠르게 선출할 수 있습니다.
참고문헌
- [In Search of an Understandable Consensus Algorithm], USENIX, (2014)
- https://www.usenix.org/system/files/conference/atc14/atc14-paper-ongaro.pdf
(더 자세하게 알고 싶다면, scalalang2님 블로그 참고
Paxos보다 쉬운 Raft Consensus
이해 가능한 합의 알고리즘을 위한 여정
medium.com
'컴퓨터 공부 > 👨💻 모각코' 카테고리의 다른 글
| 모각코 6회차 - 웹 스크래핑을 통한 정보 추출 (0) | 2022.11.30 |
|---|---|
| 모각코 4회차 - SQLD 자격증 공부 (0) | 2022.11.14 |
| 모각코 3회차 - 각자 문제풀이 (2) | 2022.11.11 |
| 모각코 2회차 - 약점체크 (0) | 2022.11.10 |
| 모각코 1회차 - 준비운동 (2) | 2022.10.05 |