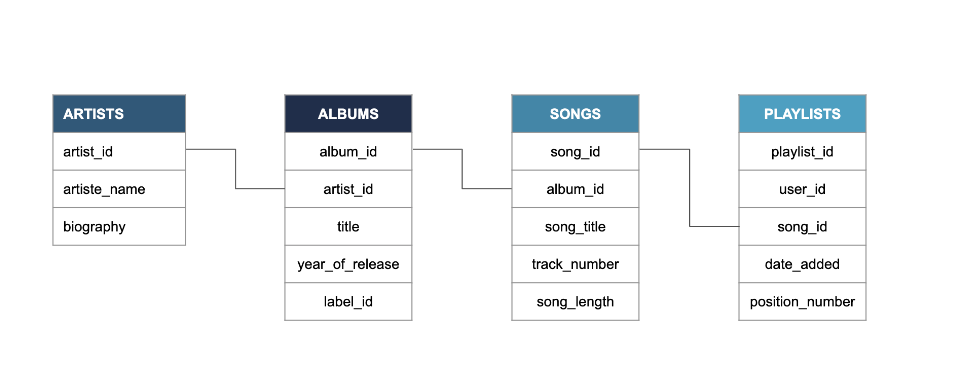
✅ RECAP 전 포스팅에서 공부한 내용을 복습해 보자. - 스케줄링의 중요성: 스케줄링은 데이터 파이프라인에서 작업을 실행할 순서를 지정하고, 의존성을 해결하며, 효율적인 작업 수행을 가능하게 한다.주요 스케줄링 방식은 아래와 같다. 1. 수동 스케줄링(Manual Scheduling): 사람이 직접 작업을 실행하는 방식: (단점) 비효율적이고 자동화되지 않는다.: (예시) 직원이 사무실 위치를 변경할 때 데이터베이스를 즉시 업데이트 2. 시간 기반 스케줄링(Time-Based Sceduling): 특정 시간에 작업을 실행: (예시) 매일 아침 6시에 직원 데이터베이스 업데이트 3. 센서 기반 스케줄링(Sensor-Based Sceduling): 특정 조건이 충족되었을 때 작업을 실행 : (예시) 직원..